N-body Simulations
What are they?
An N-body simulation approximates the motion of particles, often specifically particles that interact with one another through some type of physical forces. Using this broad definition, the types of particles that can be simulated using n-body methods are quite significant, ranging from celestial bodies to individual atoms in a gas cloud. From here out, we will specialize the conversation to gravitational interactions, where individual particles are defined as a physical celestial body, such as a planet, star, or black hole. Motion of the particles on the bodies themselves is neglected, since it is often not interesting to the problem and will hence add an unnecessarily large number of particles to the simulation.
How are they done?
The most obvious way to perform this simulation is through direct integration of the Newtonian gravitational force equation, where the total force on each particle is the superposition of the forces imparted by each of the other particles:

By calculating the net force on each particle, the new velocity and position can be calculated using a discretized time step, dt. This method is known as the brute force method: the only approximation being made is that during the time dt, the acceleration of each particle is constant. By using a small dt, this approximation becomes valid. Of course, this comes at the price of more computation to advance to a future time.
The major shortcoming of this algorithm is the asymptotic computational time, which scales as N² with N representing the number of particles. As the number of particles in the system doubles, the asymptotic computational time quadruples, which makes the algorithm unsatisfactory for large N, at least in the absence of very powerful computational systems.
How can the runtime be improved?
For very accurate results, the brute force method gives the most correct results. Unfortunately, it is very slow when the number of particles is large. A common way to improve the computational time is to implement a tree algorithm known as the Barnes-Hut algorithm, named after its creators.
In order to decrease the number of force calculations necessary per time step, one can begin to think about neglecting individual bodies that are far away from the body whose net force we are interested in calculating. Since the gravitational force decreases as 1/r², bodies that become substantially far enough from any body become significantly less important to its subsequent motion. The Barnes-Hut algorithm provides a systematic way to define "far-away" along with providing a method for approximating the force due to far-away bodies.
An oct-tree data structure is used to represent the position of the bodies in the galaxy. A finite region of space is divided into octants, each of which will hold a number of bodies. Each of these subspaces is assigned a mass, which is defined to be located at the center of mass of the bodies in that octant with a mass equal to their sum. Then, each octant that contains more than one body is again subdivided into eight smaller octants, each of which has a mass as previously defined. This process is continued recursively until each octant contains either zero or one bodies. A visual representation of this data structure is shown below in two dimensions.
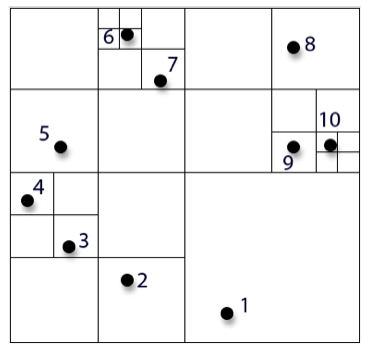
Once the tree is populated, we have to calculate the forces on each of the bodies in the galaxy. We start with body 1 and look at the first node of the tree. Then, we take the length of one side of the octant that represents the node and divide this length by the distance between the node's center of mass and body 1. This ratio is compared to a number, r, that is defined in the simulation. The greater the number, the less accurate the simulation, but the smaller the number, the longer the simulation will take. In fact, if r = 0, then the simulation degrades to the original brute force method. In general, r is defined as 0.5 for sufficient accuracy [1]. If the ratio computed is greater than r, then the node is treated as a single body, regardless of its internal composition, and the force is calculated based on the node's mass and center of mass. If the ratio is less than r, then the body and the node are still relatively close to each other, so we move down the tree from the first node into each of the children of the first node. The same algorithm is followed recursively until a node containing only one child is reached, since this represents a physical body. After this process is completed for body 1, it is repeated for each of N bodies using the same tree. After each body has an updated force calculated for the current time, the positions and velocities are updated using the same methods described in the brute-force section. Then, the time-step is advanced, a new tree is created and the process repeats for as long as desired. This process sounds generally more complicated and computationally intensive than the brute-force method, but it actually takes significantly less time on average. Recall that for the brute-force algorithm, each time-step took a time that was proportional to the number of bodies squared, N². For the Barnes-Hut algorithm, each body calculates a force with on average log(N) other bodies in the tree. Hence, the overall time for one time-step in the Barnes-Hut algorithm is proportional to Nlog(N). Asymptotically, the difference between the runtimes is substantial.
To see examples of both methods written in Java for applet deployment, head to the programming section. If you'd rather see the applets in action, go to the applets section.